接上篇《58、Pandas库中Series对象的操作(一)》
上一篇我们讲解了Pandas库中Series对象的基本概念、对象创建和操作,本篇我们来继续学习Series对象的运算、函数应用、时间序列操作,以及Series的案例实践。
一、Series对象的运算
1. 数值型数据的算术运算
Pandas的Series对象支持基本的算术运算,包括加法、减法、乘法和除法。这些运算可以在Series对象之间进行,也可以与标量(即单一数值)进行。在进行算术运算时,Pandas会尝试进行元素级别的对齐(element-wise alignment),如果Series对象的索引不同,Pandas会尝试基于索引进行匹配,或者在某些情况下使用NaN(Not a Number)来填充缺失的位置。
加法:通过+运算符或add()方法实现。
减法:通过-运算符或sub()方法实现。
乘法:通过*运算符或mul()方法实现。
除法:通过/运算符或div()方法实现。
代码示例:
import pandas as pd
# 创建Series对象
s1 = pd.Series([1, 2, 3, 4])
s2 = pd.Series([10, 20, 30, 40])
# 加法
s_add = s1 + s2
print("加法:", s_add)
# 减法
s_sub = s1 - s2
print("减法:", s_sub)
# 乘法
s_mul = s1 * s2
print("乘法:", s_mul)
# 除法
s_div = s1 / s2
print("除法:", s_div)2. 布尔索引与数据筛选
Pandas的Series对象支持基于布尔索引(Boolean Indexing)的数据筛选。布尔索引允许你根据条件表达式的结果来选取Series中的元素。当条件表达式作用于Series对象时,会返回一个与原始Series具有相同索引的布尔型Series,其中True表示满足条件的元素,False表示不满足条件的元素。然后,你可以使用这个布尔型Series来索引原始Series,从而选取满足条件的元素。
条件表达式:使用比较运算符(如==、<、>等)创建条件表达式。
布尔索引:将条件表达式的结果用作索引,选取满足条件的元素。
代码示例:
import pandas as pd
# 创建Series对象
s = pd.Series(['apple','banana','cherry','date'])
# 布尔索引选以'a'开头的元素
filtered_s = s[s.str.startswith('a')]
print("筛选结果:", filtered_s)3. 排序操作
Pandas的Series对象提供了两种排序方法:sort_values()和sort_index()。
sort_values():根据Series中的值进行排序。默认情况下,数据按升序排序,但也可以指定ascending=False进行降序排序。
sort_index():根据Series的索引进行排序。同样地,也可以指定ascending参数来控制排序顺序。
这两种方法都会返回一个新的已排序的Series对象,原始Series对象保持不变。
代码示例:
import pandas as pd
# 创建带有索引的Series对象
s = pd.Series([3, 1, 4, 1, 5], index=['d', 'b', 'a', 'c', 'e'])
# 根据值排序
s_sorted_values = s.sort_values()
print("按值排序:", s_sorted_values)
# 根据索引排序
s_sorted_index = s.sort_index()
print("按索引排序:", s_sorted_index)4. 统计信息
Pandas的Series对象提供了许多统计方法,用于计算数据的描述性统计量。这些统计方法包括:
mean():计算Series中元素的均值(平均值)。
std():计算Series中元素的标准差。
max():返回Series中的最大值。
min():返回Series中的最小值。
此外,还有其他一些常用的统计方法,如median()(中位数)、mode()(众数)、quantile()(分位数)等。这些方法可以帮助你快速了解数据的分布情况和特征。
代码示例:
import pandas as pd
# 创建Series对象
s = pd.Series([1, 2, 3, 4, 5, 6, 7, 8, 9])
# 计算统计信息
mean_value = s.mean()
std_value = s.std()
max_value = s.max()
min_value = s.min()
print("均值:", mean_value)
print("标准差:", std_value)
print("最大值:", max_value)
print("最小值:", min_value)二、Series对象的函数应用
1. 使用apply()方法应用自定义函数
apply()方法是Pandas中Series对象的一个强大工具,它允许用户应用自定义函数到Series中的每个元素。通过apply()方法,用户可以轻松地执行复杂的元素级操作,这些操作可能无法通过内置的Pandas函数直接实现。
示例:定义一个函数,该函数将Series中的每个元素平方,并使用apply()方法将其应用到Series对象上。
import pandas as pd
# 自定义函数,计算平方
def square(x):
return x ** 2
# 创建Series对象
s = pd.Series([1, 2, 3, 4, 5])
# 使用apply()方法应用自定义函数
s_squared = s.apply(square)
print(s_squared)2. 使用map()方法应用字典映射
map()方法允许用户将一个字典中的键-值对映射到Series中的元素。当Series中的元素是字典的键时,这些元素将被替换为对应的值。这对于数据转换和分类特别有用。
示例:创建一个字典,将一组数字映射到它们的字符串表示形式,并使用map()方法将其应用到Series对象上。
import pandas as pd
# 创建字典映射
mapping = {1: 'one', 2: 'two', 3: 'three', 4: 'four', 5: 'five'}
# 创建Series对象
s = pd.Series([1, 2, 3, 4, 5])
# 使用map()方法应用字典映射
s_mapped = s.map(mapping)
print(s_mapped)3. 使用str属性进行字符串操作
对于包含字符串的Series对象,Pandas提供了str属性,该属性包含了一系列用于字符串操作的方法。这些方法与Python内置的字符串方法类似,但可以在整个Series对象上高效地应用。
示例:使用str.upper()方法将Series中的字符串转换为大写,并使用str.contains()方法检查字符串是否包含特定的子字符串。
import pandas as pd
# 创建包含字符串的Series对象
s = pd.Series(['apple', 'banana', 'cherry', 'Date', 'apple pie'])
# 使用str.upper()方法转换为大写
s_upper = s.str.upper()
print(s_upper)
# 使用str.contains()方法检查是否包含'apple'
contains_apple = s.str.contains('apple')
print(contains_apple)4.pct_change()函数
pct_change()函数是Pandas库中Series和DataFrame对象的一个方法,用于计算当前元素与前一元素之间的百分比变化。它对于时间序列数据特别有用,因为它可以帮助你快速了解数据是如何随时间变化的。
具体来说,pct_change()方法计算的是当前元素与前一个元素之间的差异,然后将其除以前一个元素(得到的结果是一个比率),再乘以100(将结果转换为百分比)。第一个元素的百分比变化通常是NaN(不是数字),因为没有前一个元素可以与之比较。下面是一个简单的例子来说明pct_change()是如何工作的:
import pandas as pd
# 创建一个简单的 Series
s = pd.Series([100, 105, 102, 110, 108])
# 计算百分比变化
change = s.pct_change()
print(change)输出是这样的:
0 NaN
1 0.050000
2 -0.028571
3 0.078431
4 -0.018182
dtype: float64解释:
第一个元素的百分比变化是 NaN,因为没有前一个元素可以与之比较。
第二个元素的百分比变化是 (105 - 100) / 100 * 100 = 5%。
第三个元素的百分比变化是 (102 - 105) / 105 * 100 = -2.8571%。
以此类推...
默认情况下,pct_change() 会计算与前一个元素的百分比变化,但你也可以通过传递一个整数参数来计算与前面多个元素的百分比变化。例如,s.pct_change(2)会计算当前元素与两个前面的元素的百分比变化。
三、Series对象的时间序列操作
1. 转换为日期时间格式
Pandas 提供了一个非常方便的函数 to_datetime(),可以将 Series 对象中的字符串或其他格式的数据转换为日期时间格式。这在进行时间序列分析时非常重要。
示例:将一个包含日期字符串的 Series 转换为日期时间格式。
import pandas as pd
# 创建一个包含日期字符串的 Series
dates_str = pd.Series(['2023-01-01', '2023-01-02', '2023-01-03'])
# 使用 to_datetime() 转换为日期时间格式
dates_dt = pd.to_datetime(dates_str)
print(dates_dt)2. 时间序列的日期组件提取
对于日期时间格式的 Series,Pandas 提供了 .dt 访问器,它允许你提取日期时间对象的各个组件,如年、月、日、小时等。
示例:从日期时间格式的 Series 中提取年份和月份。
# 假设 dates_dt 已经是日期时间格式的 Series
# 提取年份
years = dates_dt.dt.year
print(years)
# 提取月份
months = dates_dt.dt.month
print(months)3. 时间序列的位移
shift() 方法允许你沿着索引轴(通常是时间轴)移动数据。这对于时间序列分析中的滞后或领先分析非常有用。示例:将时间序列数据向前移动一个单位(例如,一天)。
# 假设 dates_dt 及其对应的值 series 是我们的时间序列数据
values = pd.Series([56, 44, 79], index=dates_dt)
# 值向前移动一个单位(日期)
shifted_values = values.shift(1)
print(shifted_values)
# 计算数据的变动情况(当前数据 - 前一天数据)
value_changes = values - shifted_values
# 打印数据变动情况
print("数据变动情况:")
print(value_changes)注意:位移后的第一个值将会是 NaN,因为没有前一天的数据可供参考。
4. 时间序列的重采样
resample() 方法允许你根据指定的频率重新采样时间序列数据。这对于将高频数据转换为低频数据(如每日数据转换为每月数据)或将低频数据转换为高频数据(通过插值或填充)非常有用。示例:将每日数据重采样为每月数据,并计算每月的平均值。
# 假设 values 是每日数据的时间序列
# 重采样为每月数据,并计算平均值
monthly_mean = values.resample('ME').mean()
# 这里应该是前面56, 44, 79这一月份书所有数据的平均值
# (56+44+79)/3 = 59.666667
print(monthly_mean)在这个例子中,'M' 表示月份,'MS' 通常用来表示月份的开始,'MD' 通常用来表示月份的结束。Pandas 支持多种频率代码,如 'D'(天)、'H'(小时)等。重采样后,你会得到一个具有新频率的时间序列数据。
四、Series案例实践:股票数据分析
在本案例实践中,我们将展示如何使用Pandas的Series对象对股票数据进行分析和处理。我们将分析一个假设的股票数据集,该数据集包含了某只股票在一段时间内的每日收盘价。
1. 数据准备
假设我们已经有了一个简单的字典,它包含了某只股票几天的收盘价。
import pandas as pd
# 假设的收盘价数据
stock_data = {
'2023-01-01': 100,
'2023-01-02': 102,
'2023-01-03': 101,
'2023-01-04': 103,
'2023-01-05': 105
}
# 将字典转换为Pandas Series对象,并设置日期为索引
stock_prices = pd.Series(stock_data)
stock_prices.index = pd.to_datetime(stock_prices.index)2. 数据可视化
使用Matplotlib库来绘制收盘价的时间序列图。
import matplotlib.pyplot as plt
# 绘制收盘价的时间序列图
# 调用matplotlib.pyplot模块的figure函数创建一个新的图形窗口,并设置其大小
plt.figure(figsize=(10, 5))
# 调用Series对象的plot方法绘制时间序列图
# 这里的title参数设置了图形的标题
stock_prices.plot(title='Stock Price Over Time', grid=True)
# 设置x轴的标签,即日期
plt.xlabel('Date')
# 设置y轴的标签,即收盘价
plt.ylabel('Close Price')
# 调用plt.show()函数显示图形
plt.show()这段代码的主要目的是使用matplotlib库来绘制一个表示股票收盘价的时间序列图。通过plt.figure()创建一个新的图形窗口,并设置其大小。然后,通过stock_prices.plot()调用Series对象的plot方法,绘制出时间序列图,并设置图形的标题为“Stock Price Over Time”。接着,使用plt.xlabel()和plt.ylabel()分别设置x轴和y轴的标签。最后,调用plt.show()来显示图形。
3. 数据分析
计算每日的收益率(即相对于前一日的百分比变化)。
# 计算每日收益率
returns = stock_prices.pct_change()
# 显示前几日的收益率
print("Daily Returns:")
print(returns.head())效果: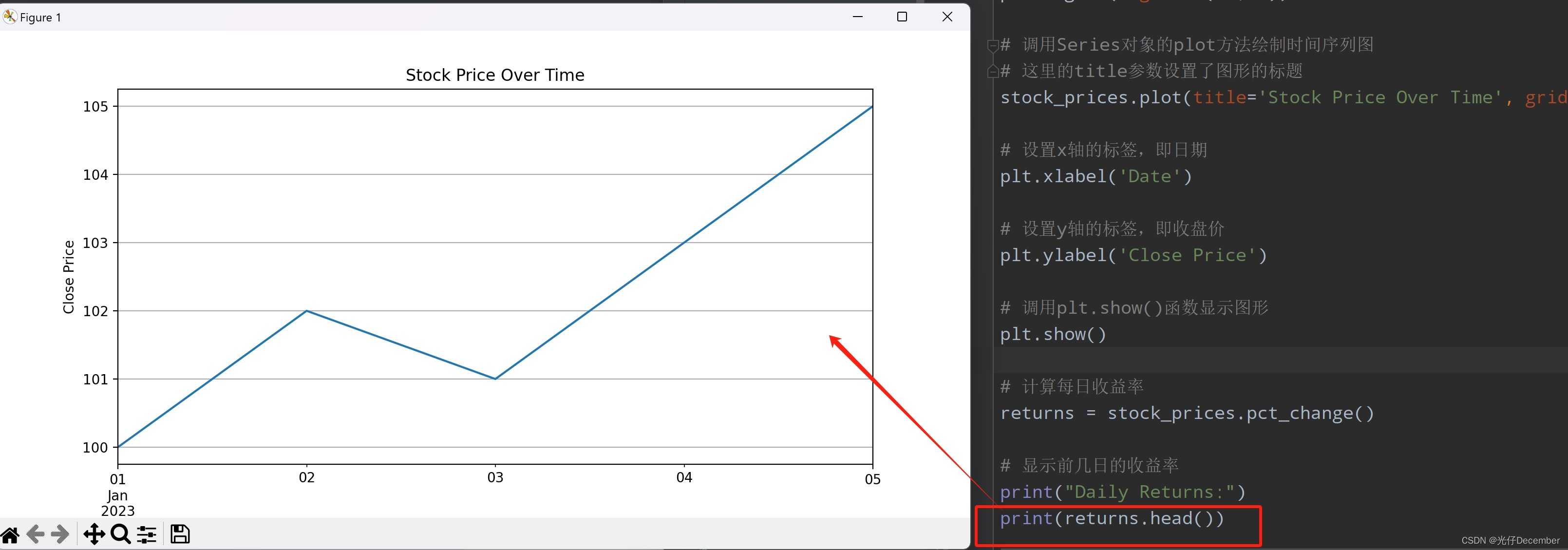
4. 结论
通过上面的代码,我们展示了如何使用Pandas Series对象来表示和分析简单的股票数据。我们首先创建了一个包含收盘价的Series对象,并使用Matplotlib绘制了时间序列图。接着,我们计算了每日的收益率,并打印了前几日的收益率。这个案例简洁明了,展示了Series对象在数据分析中的基本用法。
至此,我们完成了Series对象的所有讲解。下一篇我们来讲解Pandas库中DataFrame对象的操作。
转载请注明出处:https://guangzai.blog.csdn.net/article/details/140084333